Understanding Retrieval Augmented Generation (RAG) Systems
As the AI landscape evolves, the need for more accurate and efficient search methodologies has emerged. One such approach gaining prominence is Retrieval Augmented Generation (RAG) systems, which enable highly efficient querying and answer generation using vast amounts of stored data. In this blog post, we’ll explore how RAG systems work and provide an example of how you can implement a RAG-based chatbot for querying your private knowledge base.
What is Retrieval Augmented Generation (RAG)?
RAG systems combine retrieval-based search with language model (LLM) generation to enhance the accuracy and relevance of the responses generated. Rather than relying solely on a language model to create answers from scratch, RAG systems retrieve contextually relevant information from a knowledge base and use that data to generate the final response. This approach significantly improves the quality and trustworthiness of the answers, as the generation is rooted in factual, stored data.
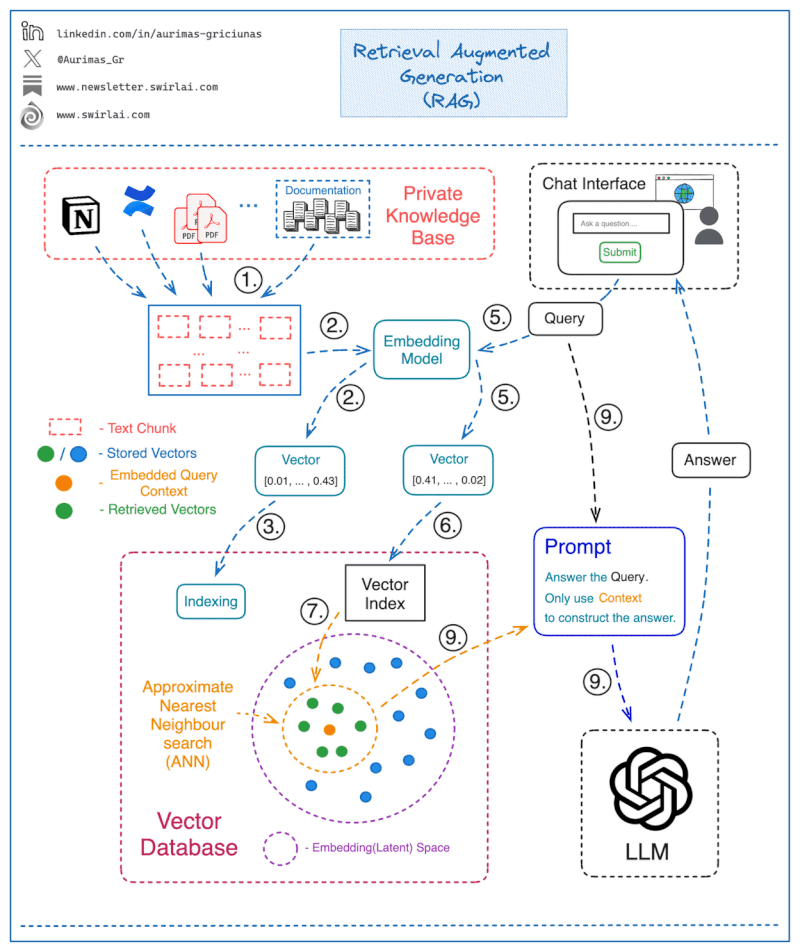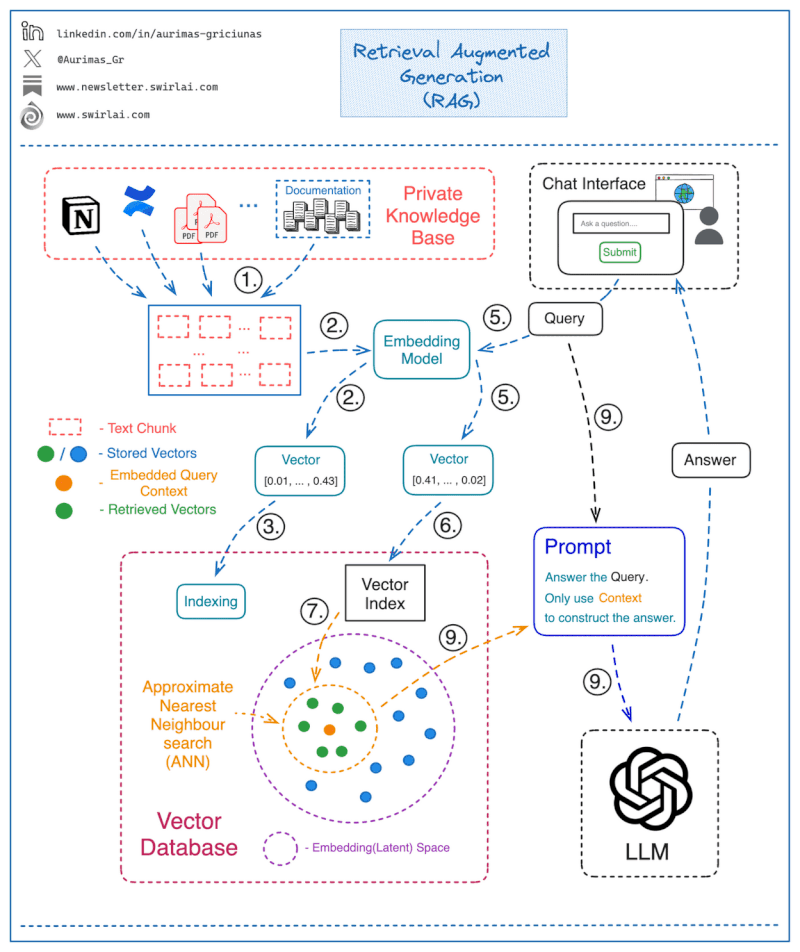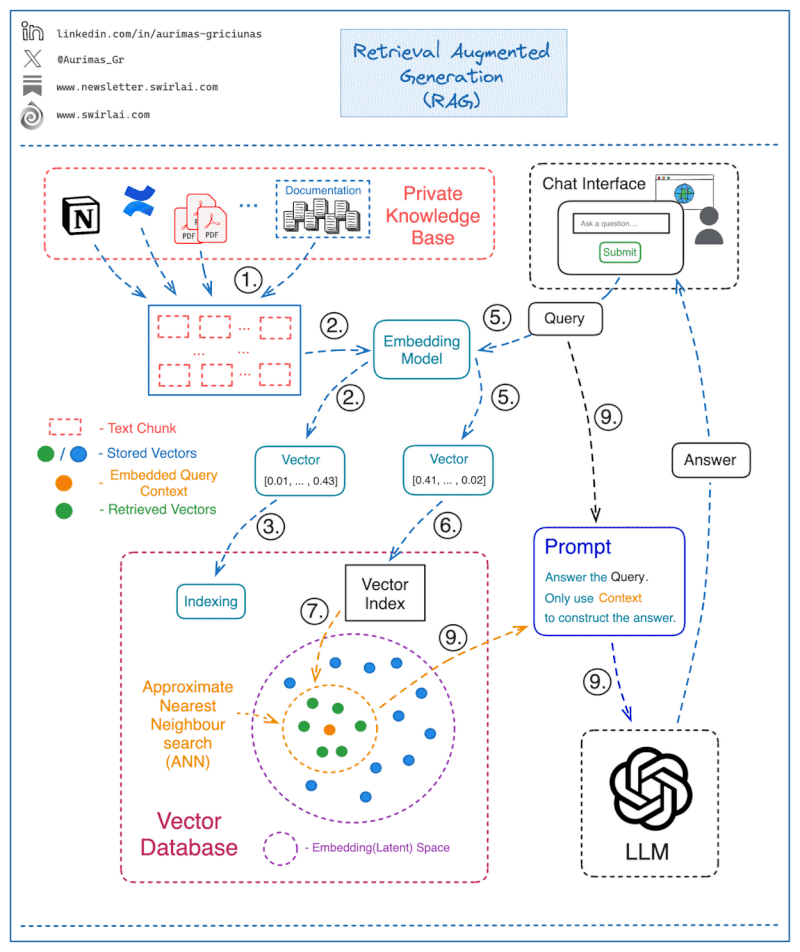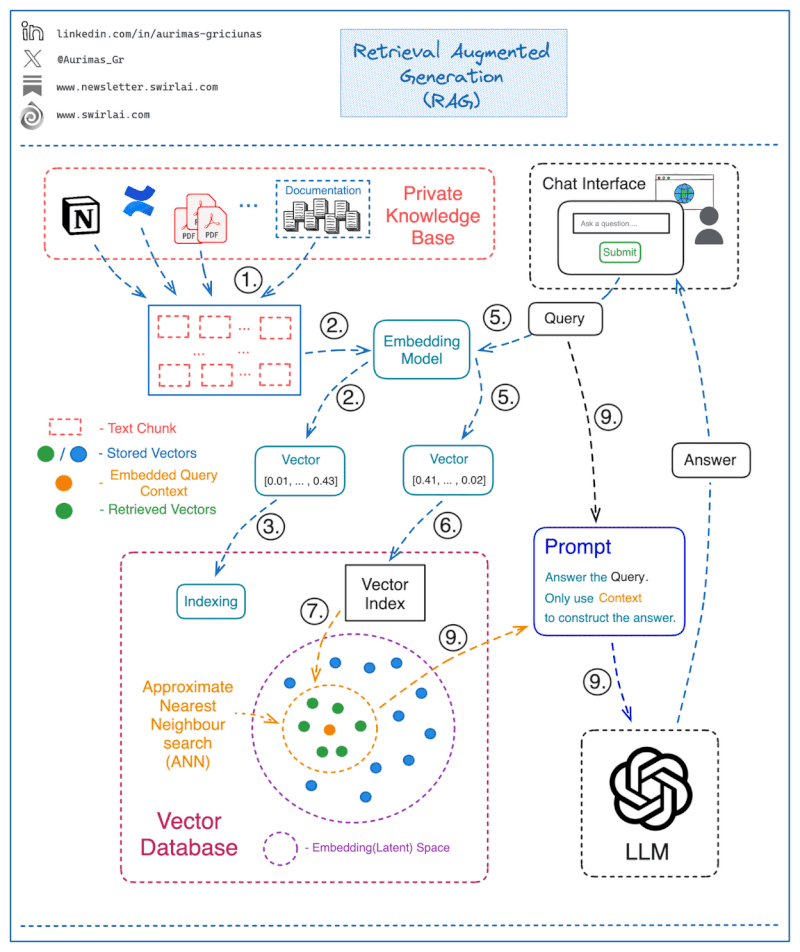
How a Simple RAG-Based Chatbot Works
Here is an example of how a RAG-based chatbot can be designed to query your private knowledge base:
Step 1: Store Knowledge in a Queryable Format
The first step in implementing a RAG system is to ensure that your internal documents are stored in a format that makes them easy to query. Here’s how it’s done:
- Chunking the Text Corpus: Split the entire knowledge base (e.g., PDFs, internal documents) into chunks. Each chunk represents a single context piece that can be retrieved later for answering a query.
- Embedding the Chunks: Use an Embedding Model to transform each chunk into a vector, which is essentially a numerical representation of the text.
- Storing Embeddings in a Vector Database: Store all vector embeddings in a vector database that will allow efficient retrieval.
- Mapping Embeddings to Text: Save the text that corresponds to each vector embedding separately, along with a pointer to the vector. This is crucial for retrieving the relevant text when answering a query.
Step 2: Constructing the Answer to a Query
Once the data is stored, here’s how the chatbot can use RAG to answer questions:
- Embedding the Query: When a user submits a question, use the same embedding model to transform the query into a vector.
- Querying the Vector Database: Use the query vector to search the Vector Database and retrieve the most relevant vectors (context) from the knowledge base.
- ANN Search for Closest Matches: The vector database performs an Approximate Nearest Neighbor (ANN) search to find the vectors that are most similar to the query vector. This is critical to ensure fast retrieval in high-dimensional spaces.
- Mapping Retrieved Vectors to Text: Map the returned vectors back to the corresponding text chunks.
- Generating the Final Answer: Pass both the original question and the retrieved context chunks to the Language Model (LLM) via a prompt. Instruct the model to only use the provided context to generate the final answer, ensuring that no out-of-context or fabricated information is returned.
Step 3: Implementing a Web Interface for Interaction
To make this process a fully functional chatbot:
- Develop a web interface where users can input their queries.
- The input will go through the above process (steps 1–9), and the final answer generated by the LLM will be displayed back to the user.
Advantages of RAG Systems
- Context-Driven Answers: By leveraging stored data, RAG systems ensure that the answers are factually accurate and relevant.
- Scalability: RAG systems can scale to handle massive knowledge bases, retrieving relevant chunks efficiently using vector databases.
- Enhanced LLM Accuracy: Since the language model relies on context provided by the retrieved vectors, it is less likely to generate incorrect or irrelevant responses.
Approximate Nearest Neighbor (ANN) Search in RAG
ANN search is at the core of how RAG systems retrieve the most relevant data. It operates by finding vectors in the database that are “closest” or most similar to the query vector in a high-dimensional space. ANN prioritizes speed and efficiency by accepting small degrees of approximation, which is essential for handling large datasets.
Why ANN Search?
Traditional exact search methods like K-Nearest Neighbors (KNN) can be computationally expensive and impractical for high-dimensional data. ANN, by contrast, focuses on balancing speed and accuracy, making it ideal for applications like RAG, where real-time query responses are critical.
Key Benefits of ANN Search in RAG:
- Efficiency in High-Dimensional Spaces: ANN handles data points with numerous attributes more efficiently than exact methods.
- Scalability: ANN algorithms scale well with growing datasets, making them suitable for modern AI applications.
- Contextual Relevance: Beyond pure matching, ANN takes into account the semantic and contextual proximity of data points.
Applications of RAG Systems and ANN Search
RAG systems, powered by ANN search, are transforming how companies manage and interact with vast datasets. Some applications include:
- Chatbots and Virtual Assistants: Query internal knowledge bases with high accuracy, as described in the chatbot example above.
- Recommendation Systems: In industries like e-commerce and music streaming, RAG systems use ANN to recommend items similar to those previously interacted with by users.
- Medical Imaging: In healthcare, RAG systems help retrieve similar diagnostic images, speeding up the diagnosis process.
- Document Search: Companies with large document repositories can use RAG systems to quickly retrieve the most relevant documents based on a user’s query.
Looking Beyond: From Naive to Advanced RAG Systems
The example we discussed is a naive RAG system, sufficient for basic querying tasks. However, to make it fit for production-grade applications, fine-tuning is essential. This involves optimizing the embedding model, vector database, and ANN search parameters. Future posts will dive deeper into these advanced techniques.
Stay tuned for more insights on transforming naive RAG systems into robust, production-ready solutions!
Conclusion
Retrieval Augmented Generation (RAG) systems are reshaping the way we think about AI-driven search and response mechanisms. By combining efficient vector search techniques with the power of language models, RAG offers a scalable, high-performance solution to query complex datasets. ANN search plays a pivotal role in ensuring that retrieval is both fast and contextually accurate.
Whether you’re building a chatbot, improving internal document search, or developing recommendation systems, RAG systems provide a powerful foundation for leveraging stored knowledge efficiently.
Want to learn more about how we implement these principles in our AI solutions? 👉 Book a meeting with Cintelis AI for a free consultation: Booking Assistant
#AI #Governance #EthicsInAI #AIInnovation #CyberSecurity #TrustworthyAI


